
Field Indexing in Ninox
Indexing fields used in queries
After analysing the performance of many Ninox solutions, there are many queries that repeatedly scan entire tables even though they return a small number of results.
Typical pattern:
- Large table (e.g. 20,000+ records)
- Query runs hundreds or thousands of times
- Each execution scans every row
This most commonly happens when no index exists on the filtered field, it can also happen when queries are written in a way that prevents indexing. It negatively impacts the performance of scripts that rely on such scans, and it can also degrade performance across the entire solution and cloud environment.
The impact on performance increases if many of these queries exist in a database and is further amplified when multiple users execute them simultaneously.
How to apply indexing to a field
To index a field:
- Open the table you are querying
- Go to the field settings
- Enable the “Index” option
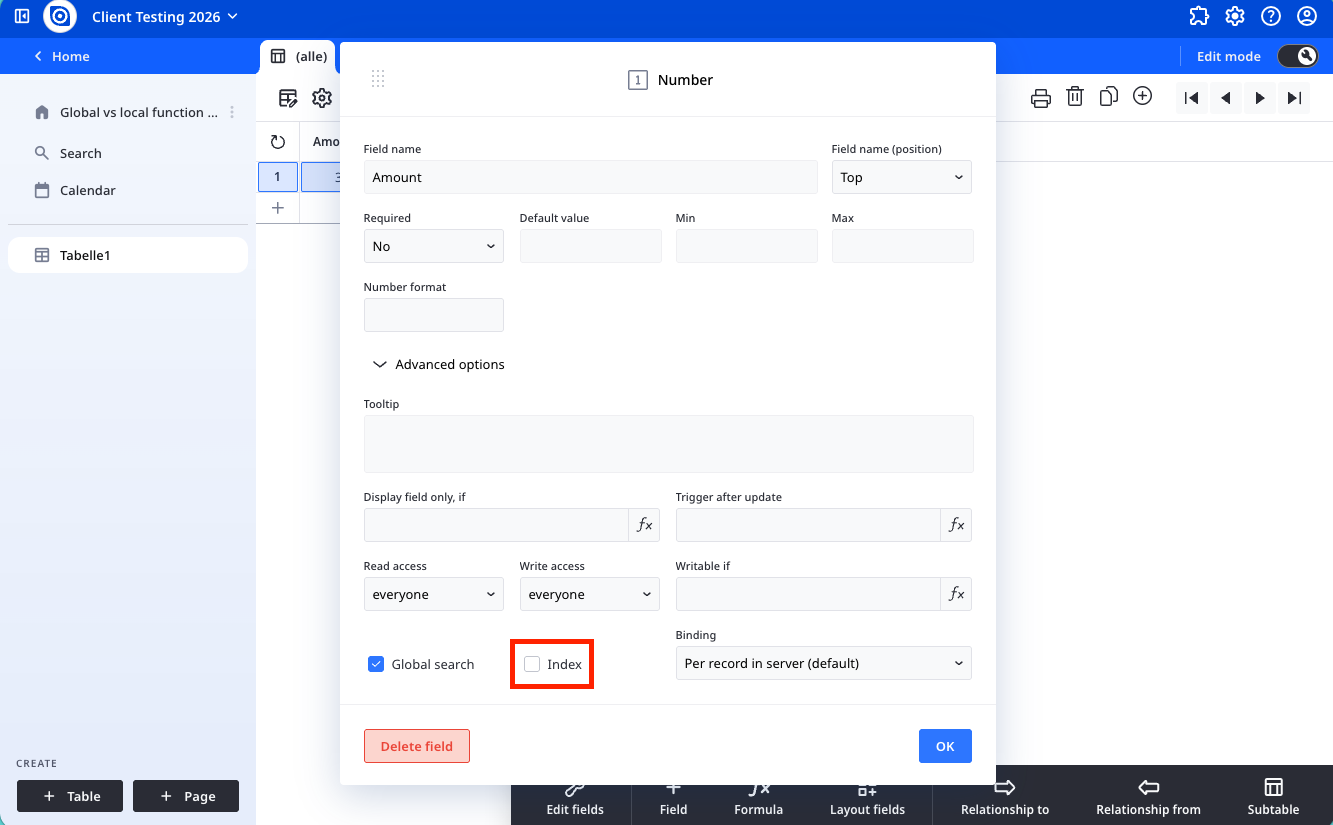
This creates a lookup structure that allows the database to find records efficiently.
When to apply indexing
Apply indexing when the following are true:
- The table contains a significant number of records (thousands or more)
- The field is used in WHERE conditions (filters) in select statements
- The query is executed frequently (e.g. in views, dashboards, scripts, automations)
For example, the table ‘Tasks’ is large and frequently queried for dashboards. Let’s say there is a ‘Status’ field with the following values:

select Tasks where Status = "Open"
Applying indexing to the ‘Status’ field would improve the performance of this query.
To further maintain performance of dashboards in large solutions with multiple users working simultaneously, it is also a good idea to follow best practices by using a client-sided select. You can read more about this in our performance documentation.
Suitable fields for indexing
- Choice fields that are very frequently used in filters and contain a clearly defined set of values:
select Tasks where Status = 1 - Dynamic choice fields that reference users or represent a dynamic selection:
select Tasks where AssignedUser = user()
When to avoid indexing
Indexes should not be added by default, as they need to be used sparingly and only when there is good reason to do so. They consume additional storage and memory for their execution. They can also increase the time taken for the completion of any write actions to the table, as any new record(s) would need to be indexed.
Here is when you do not need to apply indexing to a field:
- The table is small
- the field is rarely filtered
- the query does not run frequently
- almost all records share the same value
- there is a limited value set (e.g. Yes/No fields)
Unsuitable fields for indexing
- Fields where almost all records contain the same value:
select Tasks where Country = "DE" - Boolean (yes/no) fields with low value diversity:
select Tasks where IsActive = true
How indexing improves performance
Let’s take an example where the “Status” field is unindexed and add another based on the assigned user of a task:
select Tasks where Status = 1or
select Tasks where AssignedUser = user()
As the field is not indexed, this is how the table will be queried:
- Load record 1 → check condition
- Load record 2 → check condition
- Repeat for every record in the table
If the table has 20,000 rows: → 20,000 evaluations per query
If this runs 5,000 times: → 100 million evaluations
If you index the field, this is how the query is executed:
Execution becomes:
- Look up “Open” in the index
- Retrieve matching record IDs
- Load only those records
This jumps directly to the results, reducing execution time. You are reducing the number of scans from a potentially huge number to a much more manageable number.
More examples
There are other scenarios where indexing may not be suitable. For example, if you index a field but apply another parameter of a function to it, an indexed field will not help:
select Tasks where upper(Status) = text("OPEN")
select Tasks where someFunction(Status)
A full scan would be necessary here, as another parameter has been introduced.
You may also encounter scenarios where the best approach is to introduce a pre-computed field that consolidates values from multiple fields and can be indexed efficiently.
For example, the following query filters records based on two separate boolean conditions:
select Tasks where not Archived and not AssignedUserIndexing individual Yes/No fields such as Archived or AssignedUser typically provides limited benefit, as these fields only contain two possible values. This low value variety reduces the effectiveness of indexing and can lead to inefficient query performance.
Instead, it is often more effective to introduce a pre-computed field that combines these conditions into a single, more distinct value. Rather than using another boolean field, which is not suitable for indexing, this field should be a text field containing a clearly distinguishable value, similar to a match code.
For example, you could define a computed text field (e.g. TaskStatusCode) with values such as:
- active
- archived
- unassigned
- archived_unassigned
With this approach, your query becomes:
select Tasks where TaskStatusCode = "active"Because the field contains more varied and specific values, indexing it is significantly more effective and can lead to improved query performance.